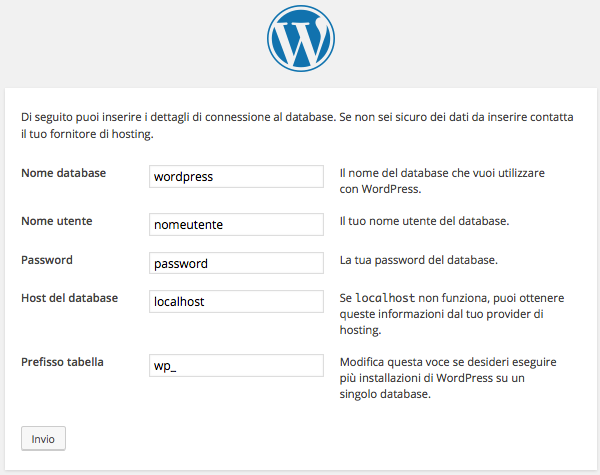
In a standard installation, you access the WordPress administration panel from the address:
However, it is possible to install WordPress in a directory other than the root, in which case the administration panel is accessible from the subfolder address:
Figura 1. Dashboard WordPress.
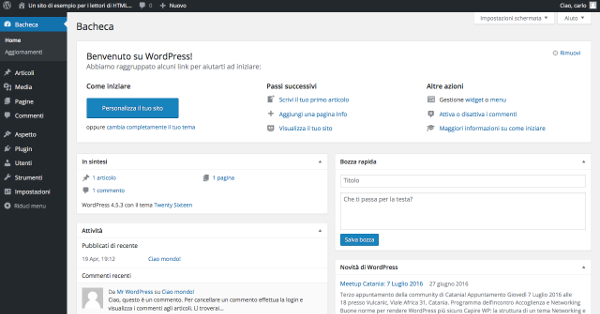
The WordPress Dashboard
The WordPress backend is made up of several areas, each with specific functions. The left column is the administration menu . This is a two-level menu, with the top-level item often grouping together similar administration pages. The central area of the main page is called the Dashboard ( Bacheca in the Italian version) and contains a series of widgets, which are areas that offer quick access to the most commonly used functions.
Figure 2. Welcome widget.
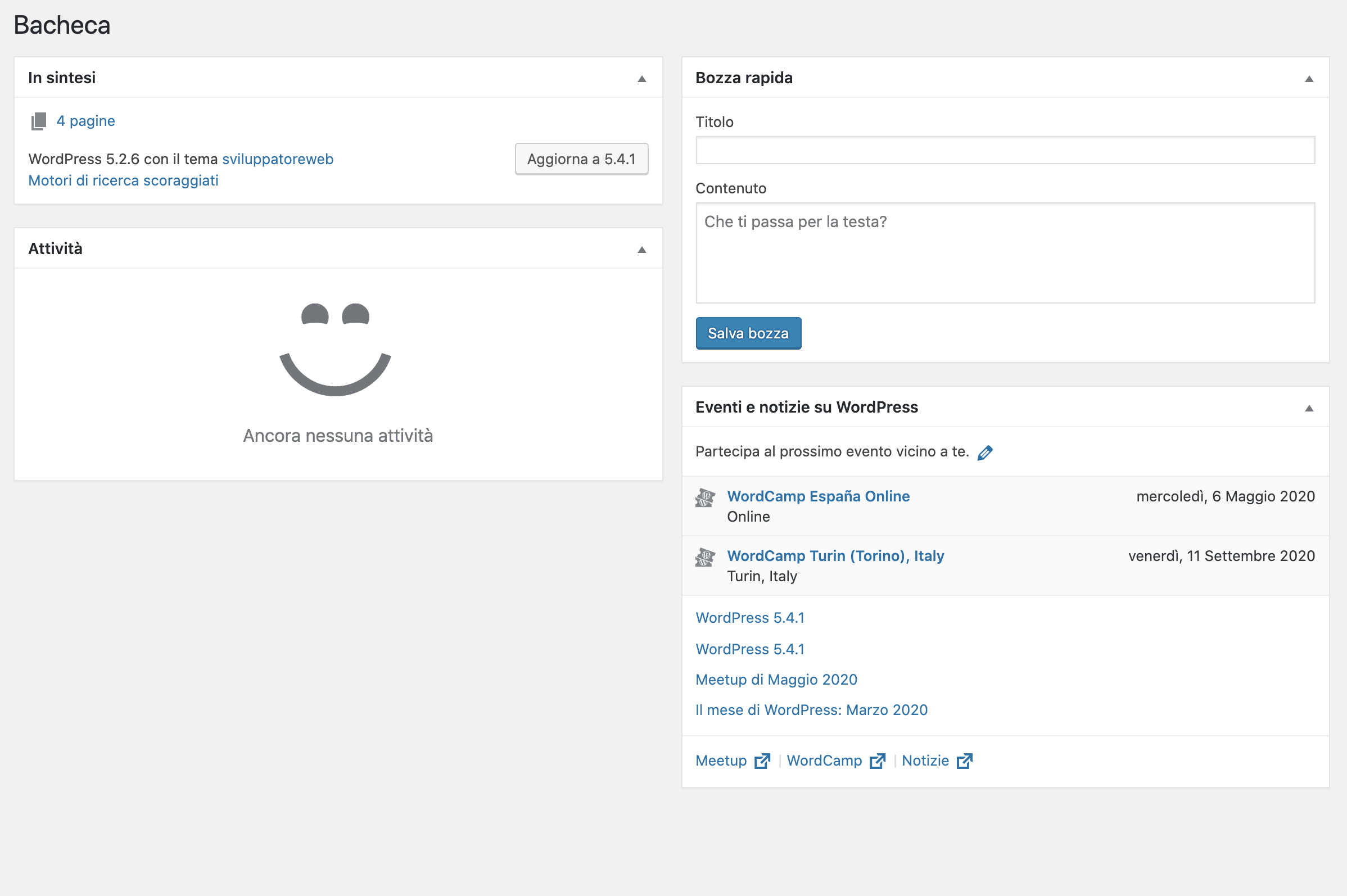
Below the Welcome widget, the default version of the WordPress Dashboard displays four widgets:
| Widget | Description |
|---|---|
| At a glance | It provides a summary of the site’s content, divided into posts, pages, and comments. The current WordPress version and the name of the active theme are provided at the bottom of the widget. |
| Attività. ( Activity ) | It provides a summary of the most recent activity, scheduled and recently published posts, as well as a list of the latest comments. |
| Quick draft | Allows you to quickly create a post draft. |
| Novità. di WordPress (WordPress News) | Displays the latest news from the WordPress.org blog in your local language. |
Figure 3. Dashboard widget.
At the top of the administration pages is the toolbar , which provides access to various administrative functions. By default, the toolbar remains visible to all authenticated users, even on the site’s front end.
Directly below this is the “Screen Settings” tab. This displays a list of widgets available for each admin page and allows you to show or hide panels, customizing the page’s appearance.
Figure 4. Dashboard widget: screen settings.

The “Help” tab finally provides support information on the administration pages.
Figure 5. Dashboard widget: Help screen.
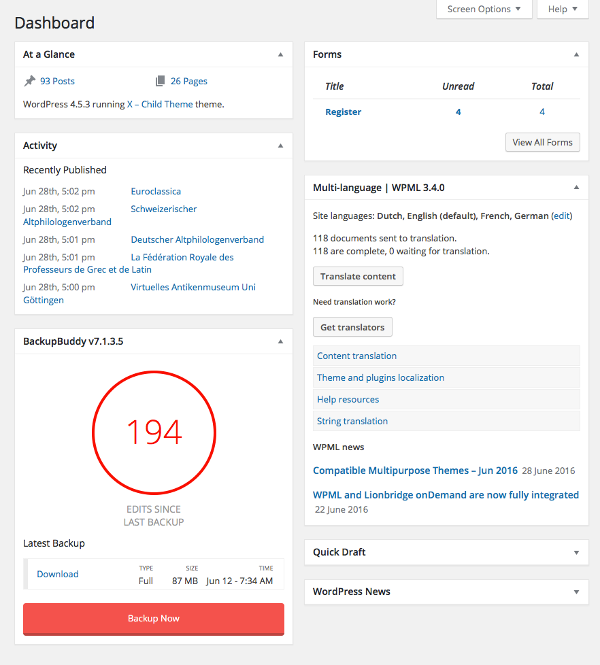
Many plugins add new panels to the default ones, enriching the home page with features and shortcuts. In addition to third-party plugins, developers can create their own widgets using the WordPress Dashboard Widgets API .
Figure 6. Boxes added by the Backup Buddy and WPML plugins.
The following are the main elements of the administration panel described in detail.
The WordPress Toolbar
The WordPress Toolbar is the ribbon located at the top of the admin panel. For authenticated users, the toolbar is also visible on the site’s front end. It primarily contains quick access menus, although its functions can be extended using the WordPress API. By default, the toolbar contains the following menus:
| Menu | Description |
|---|---|
| WordPress Logo | List of institutional links (e.g., online documentation). |
| Site Name | Back-end: Links to the site’s home page. Front-end: Displays a submenu with links to various pages in the admin panel. |
| Updates | Go to the updates page. |
| Comments | Shows the number of recent comments and links to the corresponding administration page. |
| New | Displays a submenu whose items point to the new content creation pages. |
| My Account | Displays information about the current user and links to the profile and logout page. |
Figura 7. WordPress Toolbar.

Plugins and themes can add elements to the Toolbar to make it easier to manage users with the right level of privileges.
The administration menu
The first group of items in the administration menu contains the items “Wallboard”, “Posts”, “Media”, “Pages” and “Comments”.
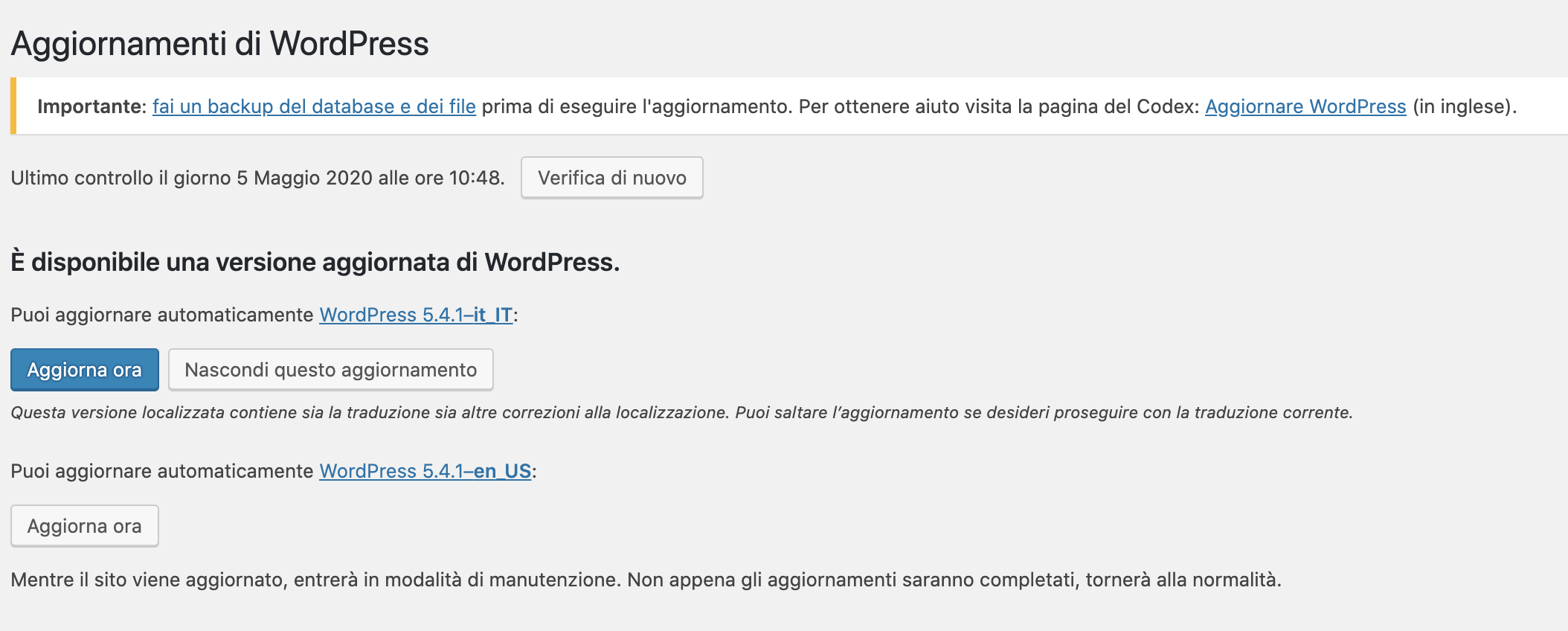
From “Dashboard” you can access “Updates.” From here you can manage all updates to your installation, from the CMS version to the plugins and themes already installed. Extensions can be updated one at a time, or selected cumulatively. Prudence recommends avoiding updates, backing up before any updates, deactivating plugins before updating them, and reactivating them one at a time after the update to check for incompatibilities and conflicts.
Figure 8. “Updates” menu.
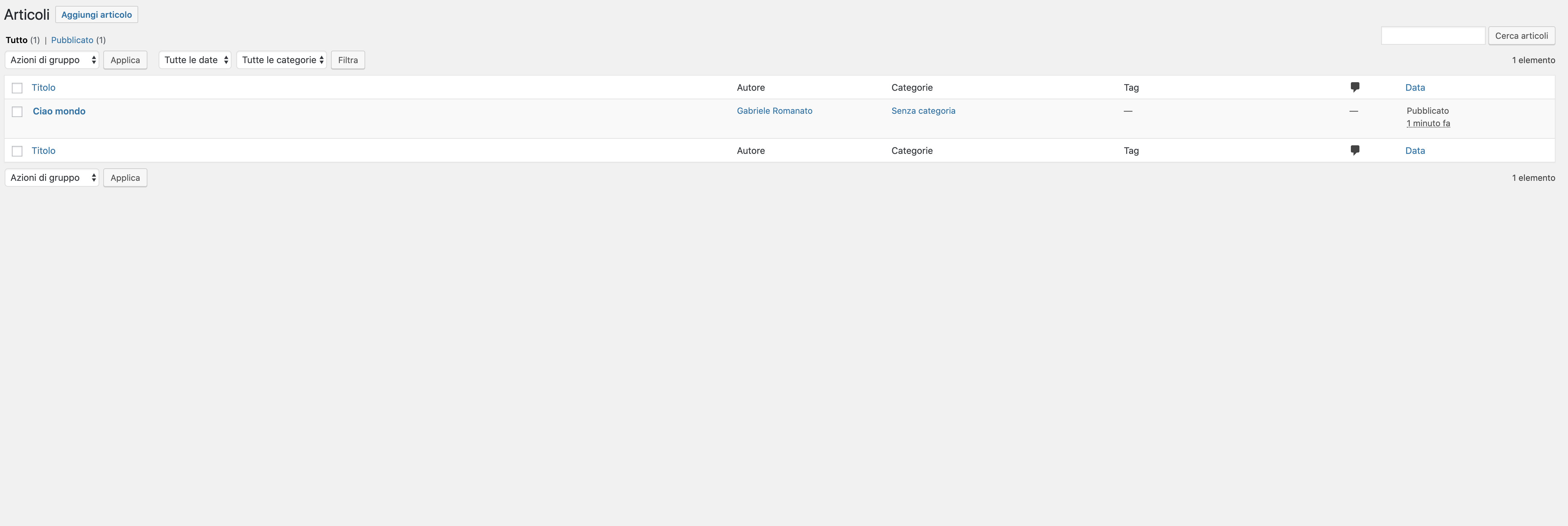
“Posts” provides access to the menu items for creating and managing posts. From here, you can access the post list, access the creation and editing page, and manage content categories and tags .
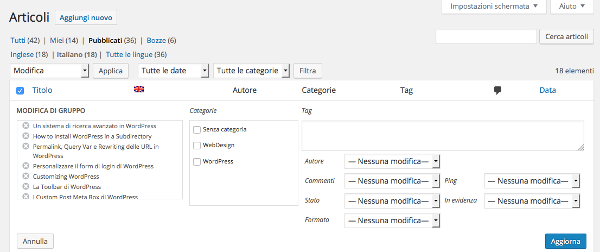
A cool feature is “Batch Actions,” which allows for cumulative changes to certain article data, such as categories, tags, author, status, format, and more.
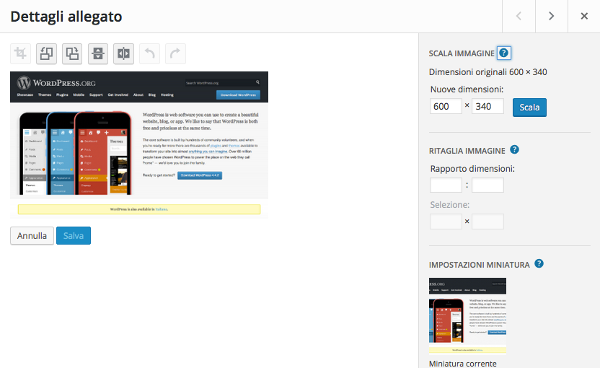
The “Media” tab provides access to media management. From here, you can select files from your desktop with a simple drag-and-drop. You can then assign data to the files, such as title, caption, alt text, and description. For images, WordPress also allows you to perform some basic editing, such as rotating, cropping, and resizing.
“Pages” and “Comments” complete the first group of items in the administration menu. Managing these two types of content is similar to managing posts.