




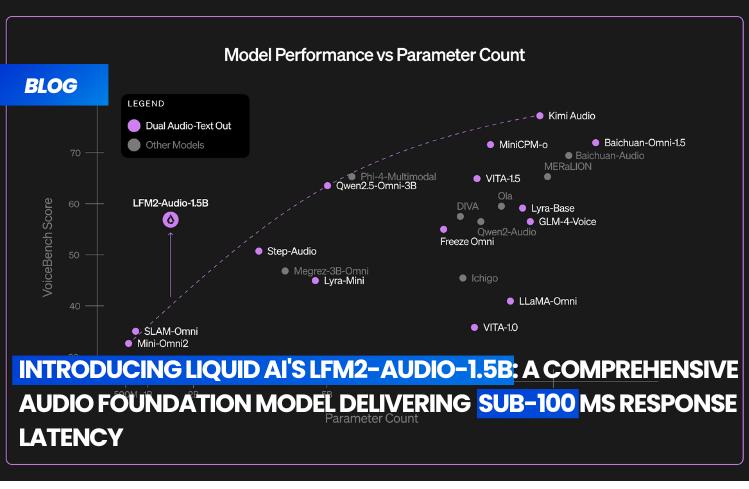
Liquid AI has introduced LFM2-Audio-1.5B, a pioneering audio-language foundation model that understands and generates both speech and text through a single, end-to-end stack. This innovation is designed to deliver low-latency, real-time performance on resource-constrained devices, expanding the LFM2 family into the realm of audio while maintaining a small footprint.
A Unified Backbone with Disentangled Audio I/O
At the heart of LFM2-Audio is a unified 1.2B-parameter backbone derived from the LFM2 language model, which treats audio and text as first-class sequence tokens. Crucially, the model disentangles audio representations, processing inputs as continuous embeddings projected directly from raw waveform chunks (~80 ms), while outputs are discrete audio codes. This approach avoids discretization artifacts on the input path while keeping training and generation autoregressive for both modalities on the output path.
The released checkpoint employs the following components:
– Backbone: LFM2 (hybrid conv + attention), 1.2B parameters (LM only)
– Audio encoder: FastConformer (~115M, canary-180m-flash)
– Audio decoder: RQ-Transformer predicting discrete Mimi codec tokens (8 codebooks)
– Context: 32,768 tokens; vocab: 65,536 (text) / 2049×8 (audio)
– Precision: bfloat16; license: LFM Open License v1.0; languages: English
Two Generation Modes for Real-Time Agents
LFM2-Audio-1.5B supports two generation modes tailored for real-time agents:
1. Interleaved generation for live, speech-to-speech chat, where the model alternates text and audio tokens to minimize perceived latency.
2. Sequential generation for ASR/TTS tasks, switching modalities turn-by-turn.
Liquid AI provides a Python package (liquid-audio) and a Gradio demo to facilitate these behaviors, with end-to-end latency below 100 ms from a 4-second audio query to the first audible response. This speed surpasses models smaller than 1.5B parameters under their setup.
Benchmarking LFM2-Audio-1.5B
On the VoiceBench suite, which evaluates nine audio-assistant tasks, LFM2-Audio-1.5B achieved an overall score of 56.78. The model card on Hugging Face offers an additional VoiceBench table and includes classic ASR Word Error Rates (WERs), where LFM2-Audio matches or improves upon Whisper-large-v3-turbo for some datasets.

The Impact on Voice AI Trends
Most “omni” stacks couple ASR → LLM → TTS, adding latency and brittle interfaces. LFM2-Audio’s single-backbone design with continuous input embeddings and discrete output codes reduces glue logic and enables interleaved decoding for early audio emission. This results in simpler pipelines and faster perceived response times, supporting ASR, TTS, classification, and conversational agents from one model.
Exploring Further
For developers eager to explore LFM2-Audio-1.5B, Liquid AI offers code, demo entry points, and distribution via Hugging Face. Additionally, you can find tutorials, codes, and notebooks on their GitHub page. Stay connected with Liquid AI on Twitter, join their 100k+ ML SubReddit, subscribe to their newsletter, and now, follow them on Telegram for the latest updates.
The post Liquid AI Released LFM2-Audio-1.5B: An End-to-End Audio Foundation Model with Sub-100 ms Response Latency first appeared on MarkTechPost.











{kind=link}