




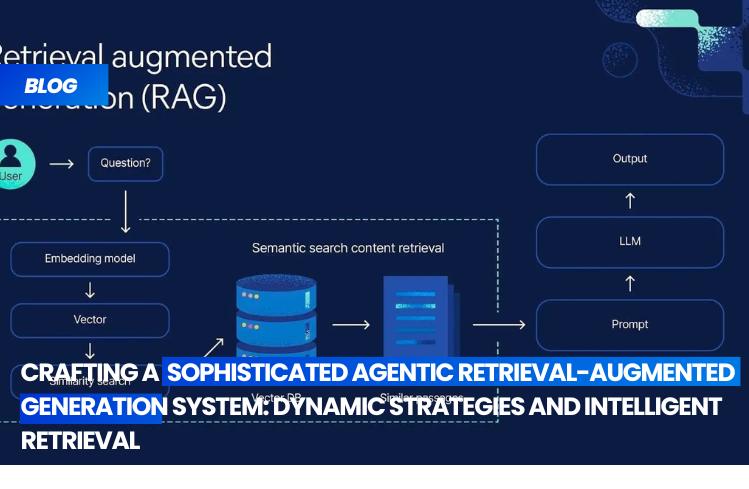
In this guide, we delve into the construction of an Agentic Retrieval-Augmented Generation (RAG) system, where the agent goes beyond mere document retrieval, actively deciding when to retrieve, selecting the best retrieval strategy, and crafting responses with contextual awareness. By integrating embeddings, FAISS indexing, and a mock LLM, we demonstrate how agentic decision-making can elevate the standard RAG pipeline into a more adaptive and intelligent system.
Setting the Foundation
We commence by defining a mock LLM to simulate decision-making processes, creating a retrieval strategy enum for varied approaches, and designing a `Document` dataclass to efficiently manage our knowledge base. This foundational setup ensures our system can handle and structure information effectively.
“`python
class MockLLM:
# …
class RetrievalStrategy(Enum):
SEMANTIC = “semantic”
MULTI_QUERY = “multi_query”
TEMPORAL = “temporal”
HYBRID = “hybrid”
@dataclass
class Document:
id: str
content: str
metadata: Dict[str, Any]
embedding: Optional[np.ndarray] = None
“`
Building the Core
Next, we initialize the Agentic RAG system, setting up the embedding model and FAISS index. Documents are added by encoding their contents into vectors, enabling fast and accurate semantic retrieval from our knowledge base. This core component is the heart of our adaptive information retrieval system.
“`python
class AgenticRAGSystem:
def __init__(self, model_name: str = “all-MiniLM-L6-v2”):
# …
def add_documents(self, documents: List[Dict[str, Any]]) -> None:
# …
“`
Enhancing the Agent’s Capabilities
To make our agent more capable, we introduce two crucial methods: `decide_retrieval` and `choose_strategy`. The first determines if a query truly requires retrieval, while the second selects the most suitable strategy: semantic, multi-query, temporal, or hybrid. This allows our agent to target the correct context with clear, printed reasoning for each step.
“`python
def decide_retrieval(self, query: str) -> bool:
# …
def choose_strategy(self, query: str) -> RetrievalStrategy:
# …
“`
Implementing Retrieval and Synthesis


We then implement the actual retrieval and synthesis processes. Semantic search is performed, branching into multi-query or temporal re-ranking when needed. Retrieved documents are deduplicated, and a focused answer is synthesized from the retrieved context. This ensures efficient, transparent, and tightly aligned retrieval.
“`python
def retrieve_documents(self, query: str, strategy: RetrievalStrategy, k: int = 3) -> List[Document]:
# …
def synthesize_response(self, query: str, retrieved_docs: List[Document]) -> str:
# …
“`
The Complete Pipeline
Finally, we integrate all components into a single query pipeline. When a query is run, the system first decides if retrieval is necessary, then selects the appropriate strategy, fetches documents accordingly, and synthesizes a response while displaying the retrieved context for transparency. This makes the system feel more agentic and explainable.
“`python
def query(self, query: str) -> str:
# …
“`
Demo and Conclusion
In a runnable demo, we create a small knowledge base of AI-related documents, initialize the Agentic RAG system, and run sample queries that highlight various behaviors, including retrieval, direct answering, and comparison. This final block ties the whole tutorial together and showcases the agent’s reasoning in action.
In conclusion, we’ve seen how agent-driven retrieval decisions, dynamic strategy selection, and transparent reasoning come together to form an advanced Agentic RAG workflow. This foundation allows us to extend the system with real LLMs, larger knowledge bases, and more sophisticated strategies in future iterations.











{kind=link}